COMP207笔记
SQL Basics
DBMS: Database Management System
tuples: 行
attributes:列
schema: " 表名(列名,列名,列名, ...) "
DDL: Data definition language 定义数据(框架)语句
- Create/alter/delete database, tables and their attributes.
DML: Data Manipulation language 操作数据(内容)语句
- Add/remove/update and query rows in tables.
DDL:
CREATE TABLE 表名(
列名1 数据类型1,
列名2 数据类型2 PRIMARY KEY,
CONSTRAINT ‘外键名称’ FOREIGN KEY(列名) REFERENCES 源表(列名)
);
CONSTRAINT ‘主键名称’ PRIMARY KEY(列名1,列名2, ...);组合主键
drop database/table ... 名称; 删除某物
alter table 表名 drop column 列名; 删除某列
alter table 表名 add 列名1 数据类型1; 加入
alter table 表名 modify 列名1 数据类型2; 改变数据类型
DML:
insert into table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...);
杂项
CREATE VIEW (CREATE VIEW <name> AS)才能创造可被再次引用的新表格
注意题目给的语句有无 “ ; ”
transactions
start transaction;
SQL statements (select...update...balabala...)
commit; / rollback;
read -> change -> write
// read: 寻址 -> ( ? ) 拷入缓存 -> 拷入变量
// write: ? 寻址 -> ( ? ) 拷入缓存
serial schedule: 串行调度——1做好再做2
ACID
A: Atomicity 原子性 a transaction 要么整个成功要么整个失败, it's an atom
C: Consistency 一致性 transaction不会使数据库变为不合法的状态,保证数据正确性和完整性。
I: Isolation 隔离性 操作可串行,互不影响
- 1 Read uncommitted -> 2 Read committed -> 3 Repeatable read -> 4 Serializable(*Isolation)
D: Durability 持久性 数据一遭更改便无从抹去
serializable 串行化
Serial Schedules 串行调度
- 好!但是慢
Concurrent Schedules 并行调度
- 问题多多。但在多用户下效率高。
对于同一个变量,并行调度其实操作的是同一片区域,于是操作会互相影响,产生错误。
Serializable Schedules 可串行化调度:
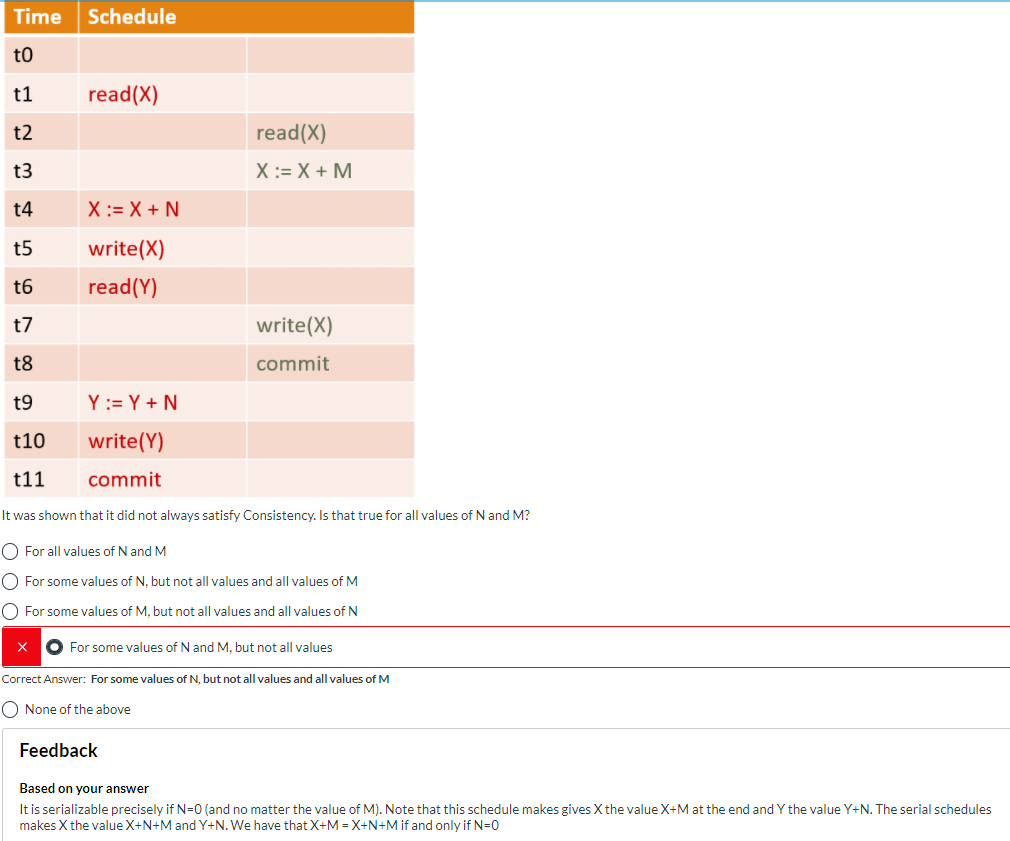
A schedule S is serializable if there is a serial schedule S’that has the same effect as S on every initial database state
至少:正确且一致(Consistency),不求满足隔离性(isolation)但可以解决。
问题:难以测试可串行化与否、非数据库操作会很复杂。
Conflict-Serializable 冲突可串行化
Conflict:对同一变量,俩操作至少有一个在写,则称这俩操作是冲突(Conflict)的(顺序有意义)。
若S经过多次1对1非冲突交换可得到串行调度S',则称S是Conflict-Serializable的,S与S'是conflict-equivalent的。
判断:
- 对于同一变量的操作,把二者不属于统一操作的 read—>write, write—>read, write—>write,也就是所有的冲突操作从前指后连起来。
- 根据 1 中操作,在操作(T1,T2,T3...)之间连线,无环量则Conflict-Serializable.
杂项
abort 终止
UNDER THE DBMS CONTROL
Errors while executing transactions
- Violation of integrity constraints, other run-time errors
Explicit request - I.e. ROLLBACK;
BEYOND THE DBMS’S CONTROL Media failures
- The medium holding the database becomes partially or completely unreadable
- Example: changes of bits, head crashes
Catastrophic events - The medium holding the database is destroyed - Examples: explosions, fires, etc.
System failures - Information about the active transaction’s state is lost - Examples: power failures, software errors
Lock 锁
Simple Locks 和锁的作用
- 当某进程对某事物操作前,会先对该事物上所锁。
- 该事物上已存在的锁和进程能否上某种锁相关。详见:锁的种类
- 如果进程无法上锁,就无法开始操作。
- 事物终会被解锁。
Deadlocks
- E.g., when using two-phase locking
- Concurrency control requests to abort transactions
2PL Two-Phase Locking 两阶段锁
In each transaction, all lock operations precede all unlocks. If a transaction start unlock, it cannot get any lock anymore.
阶段1 Phase 1: request locks
阶段2 Phase 2: unlock
使用2PL锁得到的调度不存在环。
锁的种类
sli(X) Shared Locks 读锁: 用于锁住读取操作。因为只读所以非独占。
xli(X) Exclusive Locks 写锁: 用于锁住写入操作。因为要写所以独占。
uli(X) Update Locks 更新锁: 一开始用于锁住读取操作,但可以升级成Exclusive Lock。所以可获得已被Shared Locks 锁住的事物,但是不带有分享性。
| 已有 | Shared | Update | Exclusive |
|---|---|---|---|
| Shared | YES | YES | X |
| Update | X | X | X |
| Exclusive | X | X | X |
更新锁可以有效避免死锁,更新锁之间相互排斥所以不会出现并发循环等待。同时因为可以和读锁共享,所以效率又相对较高。
Granularity 颗粒度
锁是一种用于控制进程的工具,这个工具它控制的范围可大可小,锁内的语句可多可少。
颗粒度从从大到小:Relation(表) > Block(页) > Tuple(行)
too coarse 太粗,虽然占用内存少,但是并行程度很低,比较慢。
too fine 太细,虽然并行程度高了,但是占用内存大大增加了。
同时还要避免一些可能会产生串行化问题的情况,比如一个transaction持有某个tuple的shared lock,结果另一个transaction又持有这个tuple所在relation的exclusive lock...
为了高效解决这个问题,就有了intention locks
intention locks 意向锁: 有关Granularity的锁
算是一种修饰,毕竟颗粒度是额外的性质。
IS: Intention to request a shared lock on a sub-item IX: Intention to request an exclusive lock on a sub-item
意向锁顾名思义,代表了一个意向。如果我要对某表里面的某行动手动脚,就要和表表达一个,啊,“我要进来了!”的意向。于是就搞一个意向锁出来。这样如果出现了大锁和小锁的冲突,系统就不需要整个表里一行行搜索有没有行锁,直接看有没有意向锁就完事了。
| 已有 | S Shared | X Exclusive | IS | IX |
|---|---|---|---|---|
| S Shared | YES | NO | YES | NO |
| X Exclusive | NO | NO | NO | NO |
| IS | YES | NO | YES | YES |
| IX | NO | NO | YES | YES |
log 日志
日志记录:“<...> 代表日志的记录内容”
undo log 回滚日志
回滚日志保证了原子性,因为做到一半如果出现了错误就给你滚回去了。
<START T>: Transaction T has started. <COMMIT T>: Transaction T has committed.*当T提交,所有变化都已记录,则要commit <ABORT T>: Transaction T was aborted. <T, X, v>: Transaction T has updated the value of database item X, and the old value of X was v. 用于恢复。
flush_log:将日志记录写入磁盘

redo log 重做日志
New meaning of <T, X, v>: “Transaction T has updated the value of database item X & the new value of X is v.” 用于重做committed transactions
Undo/Redo Logging
<T, X, v, w>: “Transaction T has updated the value of database item X, and the old/new value of X is v/w.”
Ensuring atomicity and durability
Undo essentially ensures Atomicity,Can ensure durability using Force
- Force:writing of updates to disk before commit
Redo essentially ensures Durability,Can ensure atomicity using No Steal
- No Steal means that uncommitted data may not overwrite committed data on disk
NO-FORCE意味着commit的东西可能没成功被写回去,那就需要redo(保证Durability);
STEAL 意味着没commit的东西可能被写回去了,那就需要undo(维护Atomicity)
(包括以下表格和一些PPT,摘自QianPin的blog Database System: Logging and Recovery 写的很好。)
| No Steal | Steal | |
|---|---|---|
| No Force | redo | redo + undo |
| Force | 不需要 | undo |
Checkpoints
They can be used to make the size of the log file smaller
for undo:
已经全部提交到磁盘了 <- Checkpoint -> 可能会出错undo
ARIES Checkpoints(for Undo/Redo logging)
<start T1>
*uncommited transactions
<Checkpoint(T1,T2...)>
*committed transactions
<END CHECKPOINT >
*没有这行相当于没有CHECKPOINT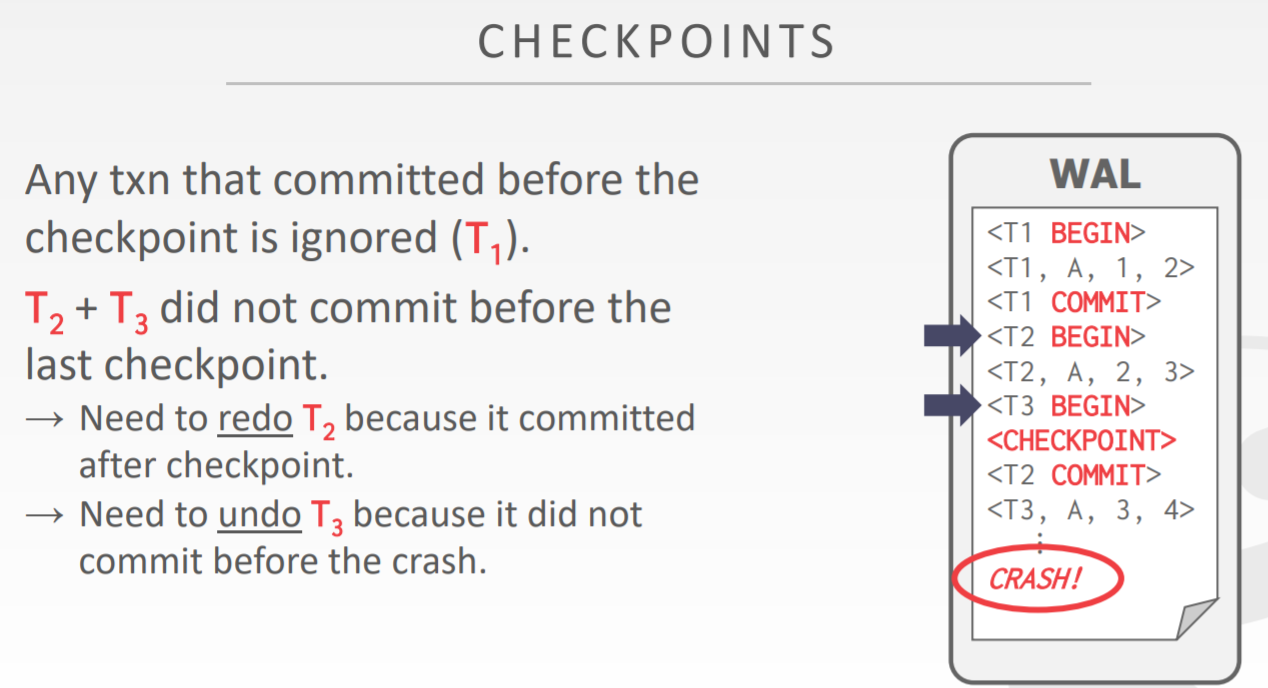
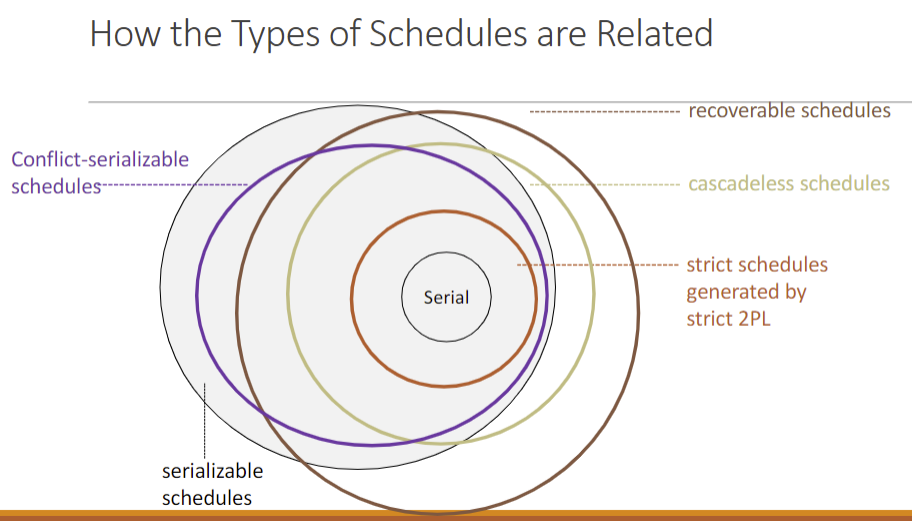
Recoverable 可恢复性
commit 不能乱c,可能出大问题 (durability and so on...
Recoverable schedules: T commits only if all Ts that T has read from have committed
Cascadeless Schedules:Read committed
- Cascadeless schedules are in general not serialisable.
Strict Schedules: Reads and writes committed
Strict Two-Phase Locking (Strict 2PL): A transaction T must not release any lock (that allows T to write data) until: T has committed or aborted, and the commit/abort log record has been written to disk.
- Strict 2PL is conflict-serialisable and strict.
- Risk of Deadlocks 死锁依旧
- Detect deadlocks & fix them (such as timestamp
- Enforce deadlock-free schedules
解决deadlock
Timeouts,Wait-for graphs(好像没什么用,只是能看环),Timestamps.
Timestamps 时间戳
Each transaction T is assigned a unique integer TS(T) upon arrival.(时间戳)
If T1 arrived earlier than T2, we require TS(T1) < TS(T2) *越小越早
- Wait-Die Scheme:older
transactions always wait for unlocks
- T1 wait,T2 roll back (die.
- Wound-Wait Scheme:older
transactions never wait for unlocks
- T1 do,T2 wait for T1
Read Time of X: RT(X) Timestamp of youngest transaction that read X *读取X的T的最大(最迟)时间戳
Write Time of X: WT(X) Timestamp of youngest transaction that wrote X *写入X的T的最大(最迟)时间戳
Requests:
If T1 requests to read X: Abort & restart T1 if WT(X) > TS(T1) *说明有小辈提前写过了,值变了,要坏事。
If T1 requests to write X: Abort & restart T1 if RT(X) or WT(X) > TS(T1) *说明有小辈提前读/写过了,要坏事。
Timestamp-based Scheduling
Nice properties: ◦ Enforces conflict-serialisable schedules ◦ Deadlocks don’t occur
Bad properties: ◦ Cascading rollbacks ◦ Starvation can occur (cyclic aborts & restarts of transactions)
MVCC Multiversion concurrency control:
写入不覆盖,而是创建新版本。读取最新版本。
For writes: Abort & restart T1 if RT(X) > TS(T1) and otherwise, grant request For reads: Always granted
SQL query
Basic relational algebra:
Selection (𝜎) 𝜎condition(R): 将符合条件的行从R中选出
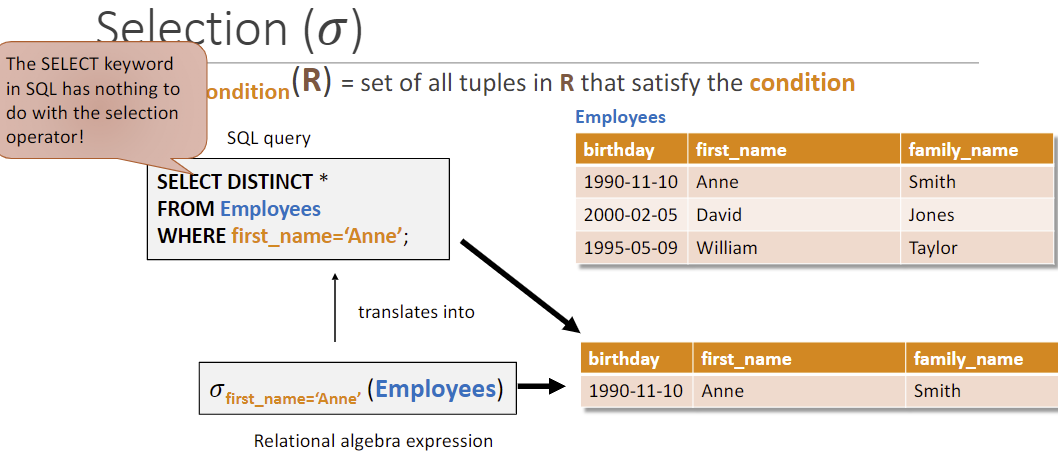
Projection (𝜋) 𝜋xx(R): 将R中的xx作为列选出
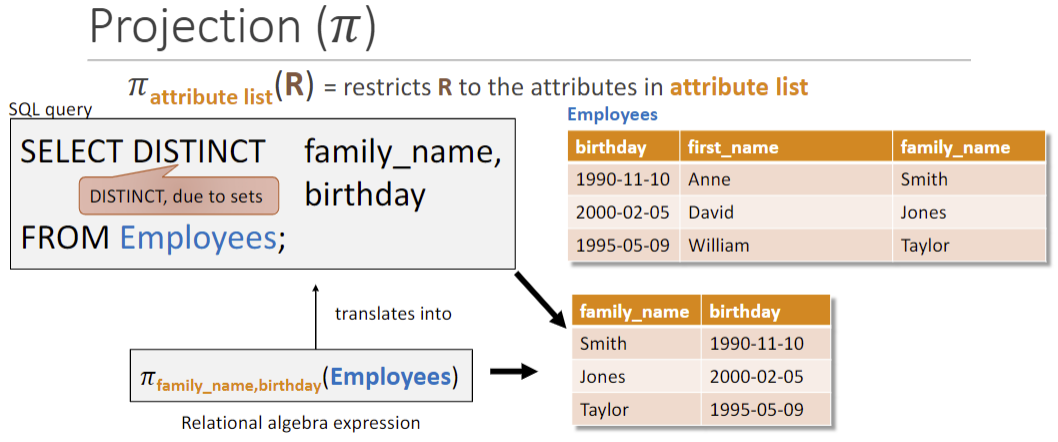
Cartesian product (×) 两边互增的合并(不相关就是列数相乘,1对n)
select * from a,b = a×b

Union (∪) 多次操作结果叠放
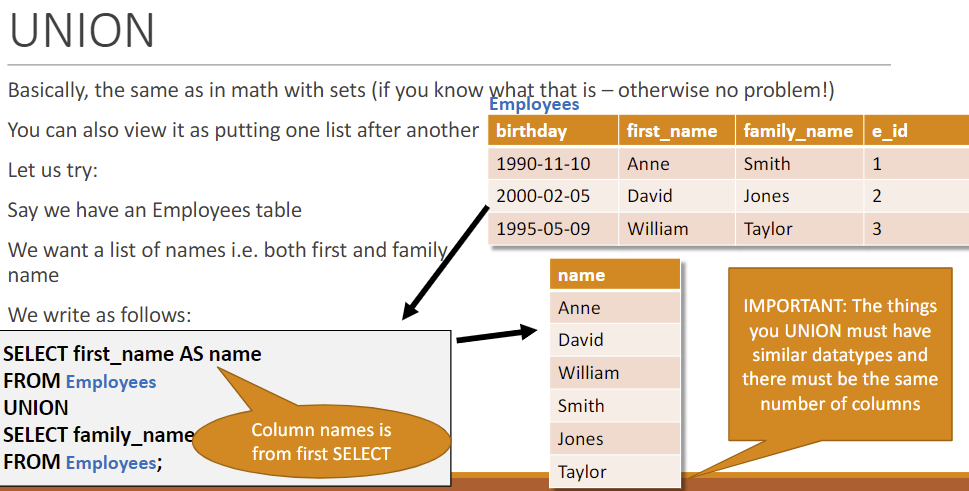
Renaming (𝜌) 𝜌xx->yy(R): 将R中的xx重命名为yy
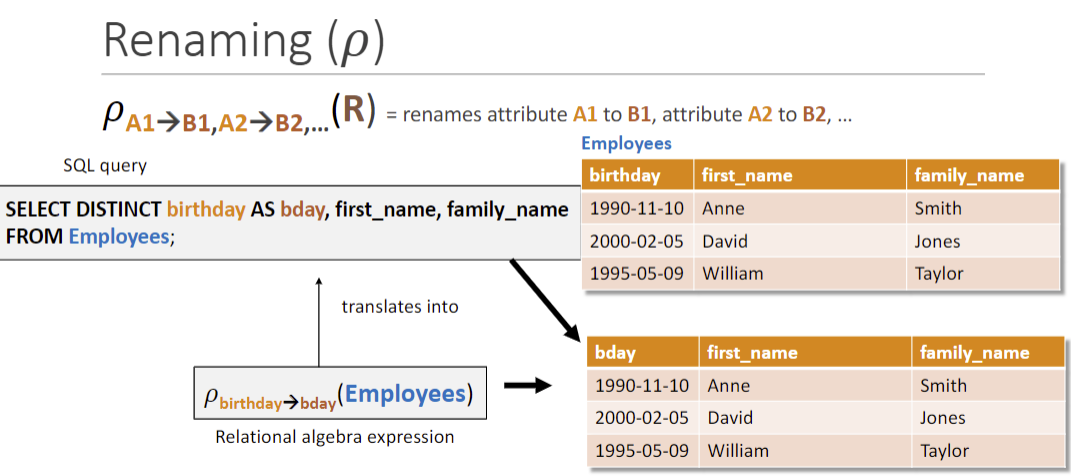
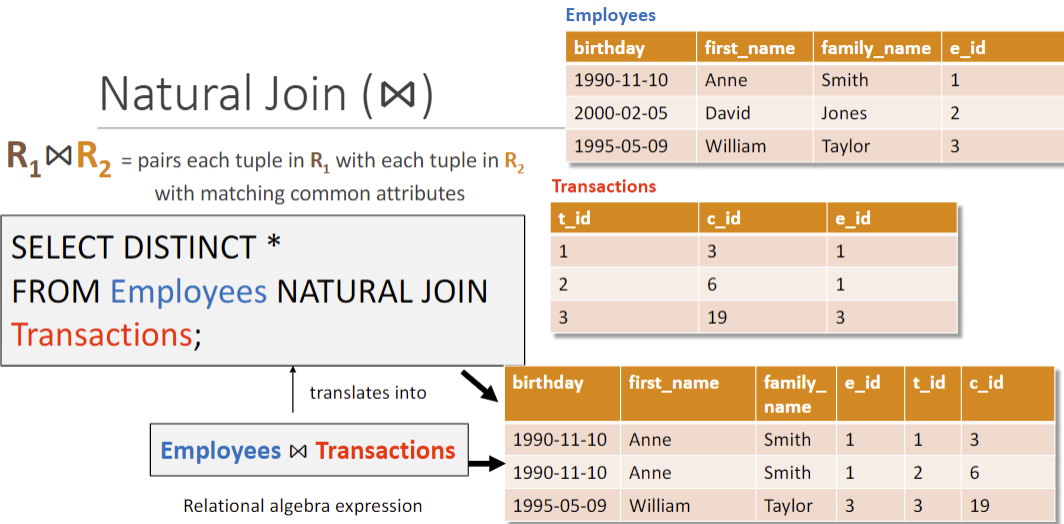
Natural join (⋈) 选出有相同公共属性的行合并(会受𝜌影响)
自然连接是在广义笛卡尔积R×S中选出同名属性上符合相等条件元组再进行投影,去掉重复的同名属性组成新的关系。
但如果没有公共属性则变为笛卡尔积。
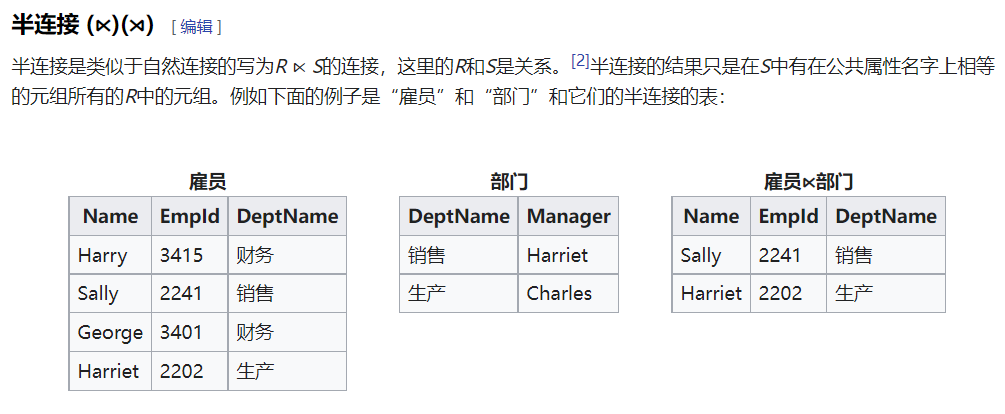
Semijoin (⋉) Natural join,但是只返回左边表的值。
各类连接总结 https://www.cnblogs.com/wishyouhappy/p/3678852.html
index
Forms of Indexes:
B+ Trees
Good if selection condition specifies a range
Most widely used
Hash tables
- Good if selection involvesequality only
B+ Tree
从叶子朝向根节点,还有一些线性扫描之类的……按照直觉来就完事了
老师:性质全按网站来:https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
Optimising query plans
PPT 不长 https://liverpool.instructure.com/courses/46572/pages/optimising-query-plans?module_item_id=1218348
data 数据
structured,semi-structured,unstructured data、
structured 结构化
- Data has to fit to schema 存成表了
- highly efficient query processing 好查,快速
unstructured 非结构化
- Completely free on how to organise data 形式随心所欲
- No description of structure or data: programs have to know how to read & interpret the data 无结构,读取需引入读取规则
semi-structured 半结构化
- Self-describing: no schema required 有结构,不是表
- Flexible: e.g., can add & remove attributes on demand 较为灵活
半结构化数据一般都是一种树形结构
- Leaf nodes have associated data
- Inner nodes have edges going to other nodes
- Each edge has a label *关系
- root:No incoming edges;Each node reachable from the root
例子:XML, JSON,Graphs...
XML Extensible MarkUp Language 可扩展标记语言
XML语法:
树:
一个element(元素)东西:
<东西>...</东西>- ... 中包含了该"东西"节点可访问到的所有子结构
东西若有(Attributes)属性:
<东西 大小=“这么大” 材料=“你妈”>
Attributes 和 Element 的区别:
一个Element可以有多个相同(指child名)的子Element,但Attributes不会重复。
其他:
- 头部声明:
<?xml version="1.0" encoding="utf-8" standalone="yes" ?>
XML结构:
1 | <?xml version="1.0" encoding="utf-8" standalone="yes" ?> |
XML遍历:平面迷宫,逆时针绕一圈回到root
实现xml结构有两种方式(规范),DTD 和 XML Schema
DTD: Document Type Definitions
定义方式:
1 | <!DOCTYPE root tag name [ |
例子:(#PCDATA=Parsed Character Data 可解析文本,不含有子元素)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
<bookinfo>
<title>计算机导论</title>
<author>丁跃潮等</author>
<publish>
<publisher>高等教育出版社</publisher>
<ISBN>7-04-014768-8</ISBN>
<pubdate>2004.6</pubdate>
</publish>
<price>19.7</price>
</bookinfo>
可见,DTD是写在xml主体前的一种类似于头文件的东西,我们先读取DTD,这样我们就知道底下那个XML结构里面的东西都是些啥了。
一些数量规则表示 (name, phone?, email?, teaches*, ... ) 这种 *: indicates zero or more occurrences for an element; 出现0~n次 +: indicates one or more occurrences for an element; 出现1~n次 ?: indicates either zero occurrences or exactly one occurrence for an element. 出现0~1次
Attribute Data types 数据类型
CDATA: character data, containing any text.
ID: used to identify individual elements in document
- You can not define what type you are pointing at exactly, but just that it is some ID for some object
List of names: values that attribute can hold (enumerated type)
- Format: (en1|en2|...) meaning the value can be either en1 or en2 or ...
IDREF/IDREFS: must correspond to value of ID attribute(s) for some element in document
About ID and IDREF/IDREFS
就像数据库里的 primary key 和 foreign key.

Two levels of document processing
well-formed and valid. 格式良好和有效的
Non-validating processor 只会检查文件是否满足 XML document 格式的要求,比如所有元素都在一个根元素里。这是 well-formed
Validating processor 还会检查DTD/XML Schema, 确保这个文件能用——valid.
XML Schema
考试不作要求,待会儿再看。
XPath
测试:https://www.videlibri.de/cgi-bin/xidelcgi
对于一个已存在xml文件,每一个元素/属性都有其地址用于查找。我们可以像windows系统文件的地址一样作表示。
Attributes: replace the last tag name by @Attribute name
考虑这样一个XML:
1 | <lecturers> XPath: |
Wildcards 通配符
A wildcard (*****) can be used to stand for any tag name or attribute name
以上述XML为例,
/lecturers/lecturer/@* returns ”123”, “180”
/lecturers/lecturer/* return all elements directly below lecturer elements
More advanced
对于任意的XPath,满足以下格式:
/axis1::E1/axis2::E2/axis3::E3/.../axisn::En
" axis i :: " : 类型标识符,例如E2是一个Attribute, 则 “axis2::” = “@”
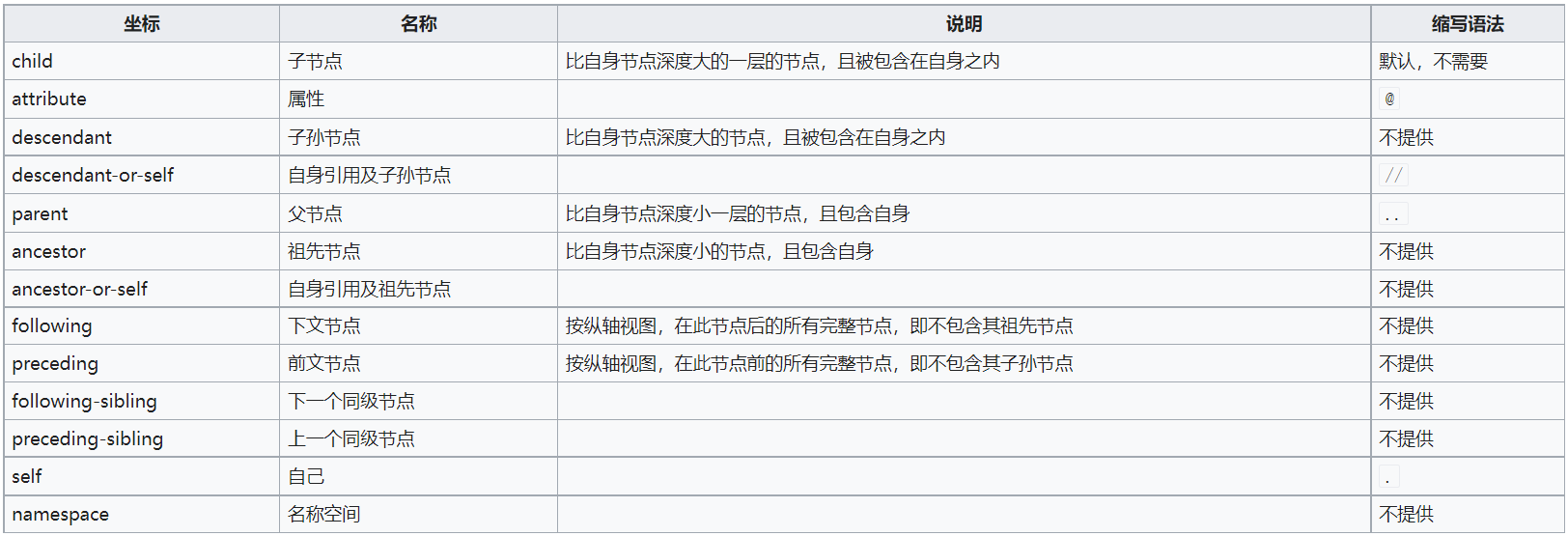

Conditions 条件
/axis1::E1[C1]/axis2::E2[C2]/axis3::E3[C3]/.../axisn::En[Cn]
example : //book[category=“CS”]/title
All titles of books in category “CS”
...E[i]: true if current node is the i-th E-child of its parent
//*[category="CS" or category="Scifi"][1]
//*[category="CS" or category="Scifi"][last()]
...E[string]: true iff string is not ”” //book[@price/data()] returns the books with a non-empty price attribute
...Expath: true iff the xpath gives a non-empty node-set //book[category]/title returns the titles of all books that has a category //book[@price] returns a book if it has a price attribute
XQuary 菜鸟教程
测试:https://www.videlibri.de/cgi-bin/xidelcgi
对于一个已知的XML文件,doc() 函数用于打开 "balabala.xml" 文件——doc(example.xml)
我们在doc()后面添加路径来查找元素:doc(example.xml) XPath 例:doc(example.xml)/element1/element2
“$”用于定义变量
let variable := XQuery expression
在地址前加$, 相当于把返回结果当作变量,于是可以比较:$s/year >= 2
XQuery 有FLWOR, 是 “for、let、where、order by、return” 的缩写。
这都是可用于 XQuery 表达式以便得到更精确结果的子句。
XPath/XQuery expressions can be used as conditions, Interpreted as true if the result is non-empty
... where $s/module return true if s/module exist.
还可以加 some/every $var. 例:
let $uni_doc := doc(”mydoc.xml") for $l in $uni_doc/university/lecturer where every $m in $l/teaches satisfies $m/year <= 2 return $l/name
More advanced
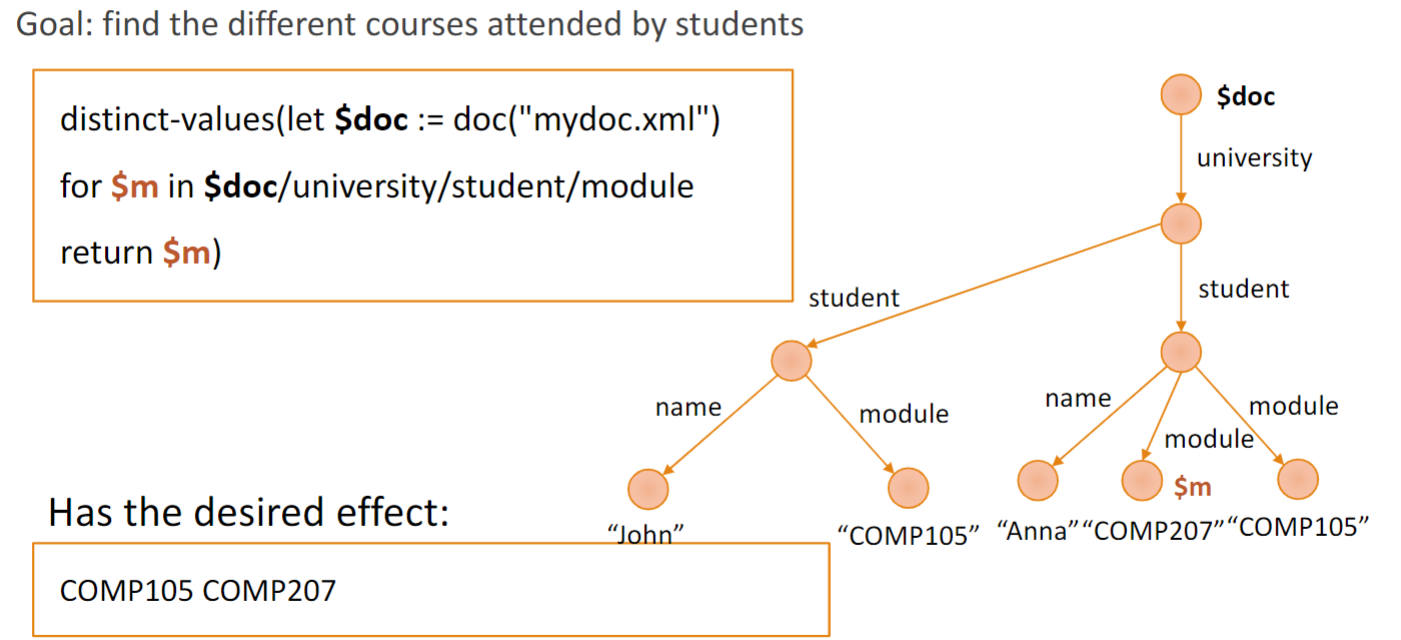
Goal: return all pairs of title and author, sorted by author name descending (ascending is default)
let $doc := doc("mydoc.xml") for $b in $doc/books/book for $author in $b/author order by $author descending return <pair>{$b/title}, {$author}</pair>


noSQL 非关系型数据库
NoSQL databases are often distributed 分布式的
Designed to guarantee: Availability: every non-failing node always executes queries Consistency: every read receives the most recent write or an error Scalability: more capacity (users, storage, ...) by adding new nodes High performance: often achieved by very simple interface(e.g., support lookups/inserts of keys, but do this fast) Partition-tolerance: even if nodes (or messages) fail, the remaining subnetworks can continue their work
The CAP Theorem:
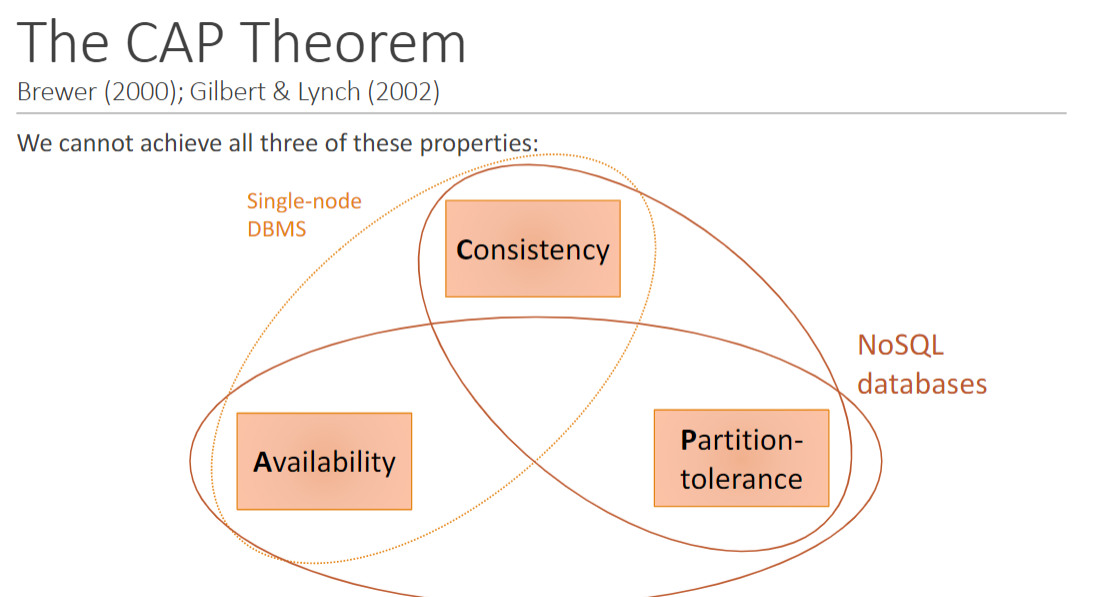
BASE
NoSQL databases drop ACID and often provide the weaker guarantees of BASE:
Basically Available Soft state Eventually consistent
Soft state & eventual consistency: the database state might occasionally be inconsistent... but it will eventually be made consistent
NoSQL的各种类型:

Key-Value Stores
find(k): returns value for key k write(k, v): inserts value v under key k
可以理解为key是数组下标
PPT里的解释和图有点跳步骤,我的建议是看 DynamoDB实现原理分析
Data analysis
我们平时使用的一些数据库的操作,如果放在那种现实中的,大量数据的公司级别数据库应用里,其规模效应会造成很多问题。
Queries in these applications tend to... ◦ be complex: use aggregates & other advanced features ◦ Examine large parts of the data
这种操作常常需要大面积的检索,应该避免在多用户DBMS上出现
Data Warehouses:为了支持Data analysis而建立,通常集成了很多数据源,作为操作者和数据库的中转站。那些日常操作就需要通过它实现。
OLTP (Online Transaction Processing,联机事务处理) 面向用户,即顾客,被用于日常事务的查询和处理。
- queries and updates that can be executed fast
- affect a small portion of a database
- consists of many queries at once, but where each are typically simple
OLAP (Online Analytic Processing,联机分析处理) 面向市场/面向分析,使用者是数据行业从业者(knowledge worker)
- Refers to the process of analysing complex data stored in a data warehouse
- Often involving GROUP BY and some WHERE clause and can depend on very much data
Star Schemas 星形模式
参考:数据仓库与OLAP
Star Schemas 是 One of the most common data warehouse architectures
它有多个Dimension tables: describe values along each axis
它有一个Unique 的 fact table: contains points in the data cube
- data cube:fact table 包含所有维表的主键,这些主键形成了一个n维空间,也就是data cube,主键坐标确定了每行Dependent Attributes在cube中的位置。
用sql的话说,所有的foreign key共同组成了fact table的primary key。(再加上汇总数据Dependent Attributes,通常是numeric value.
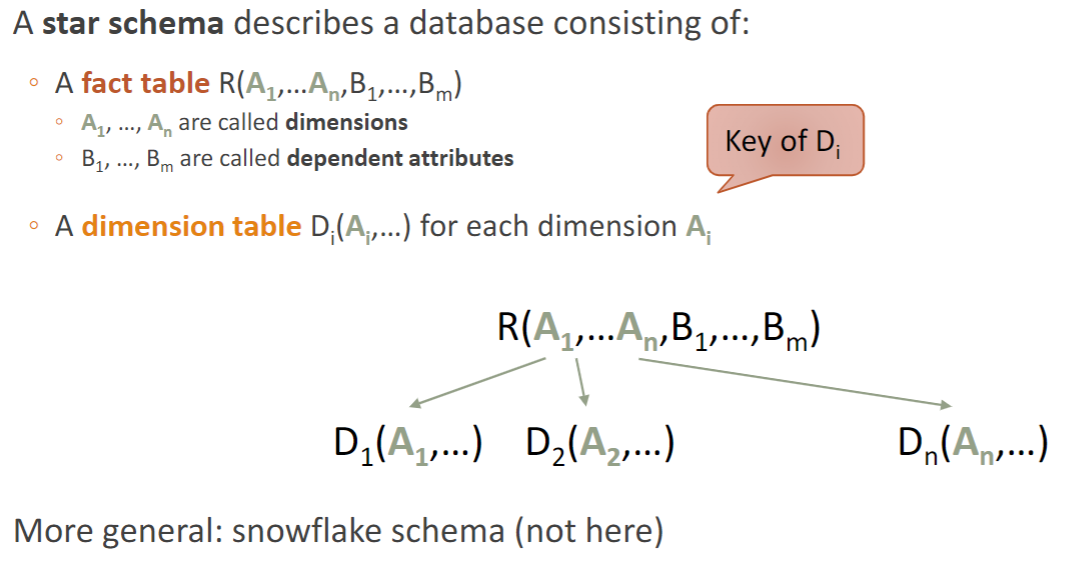
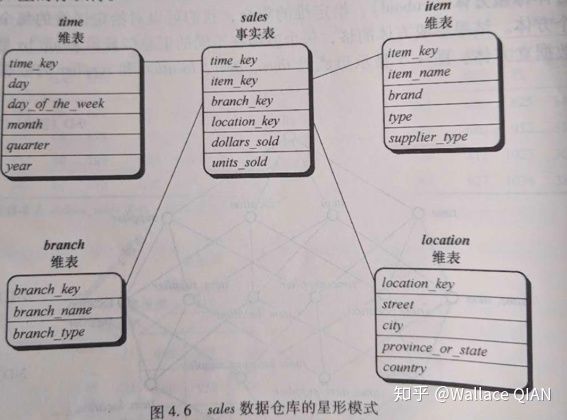
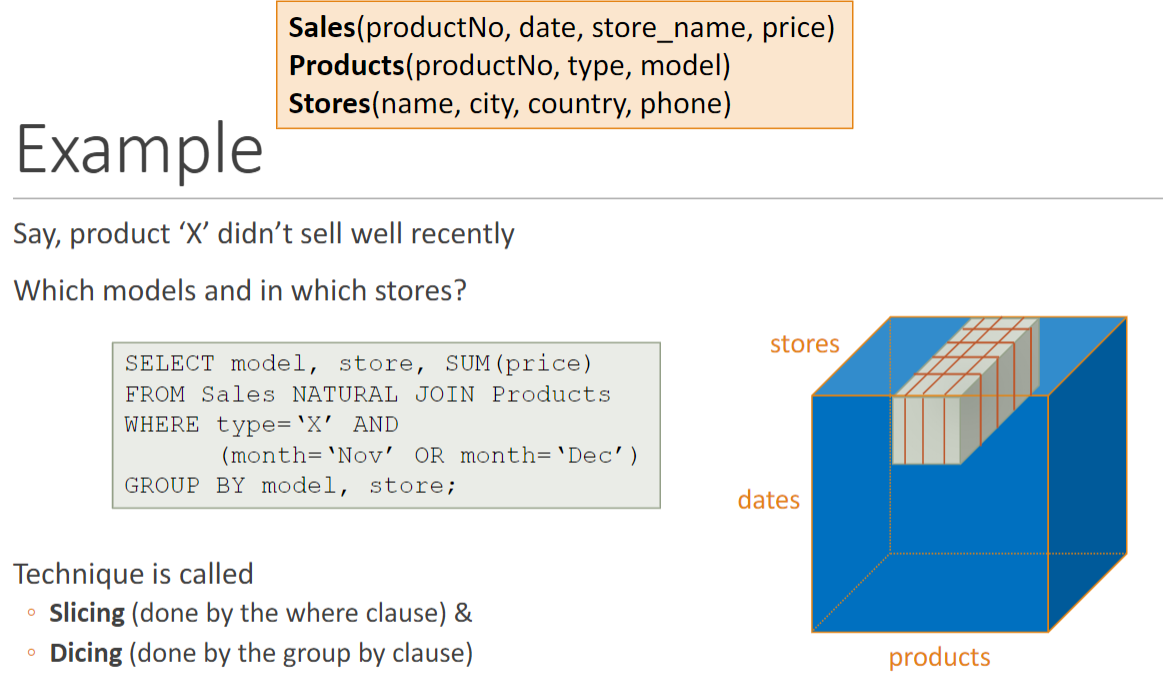
Characteristics of Star Schemas
Key feature: denormalised schema 非正规模式 ◦ Main data in one table (fact table) ◦ Rest of the data can be joined with fact table very quickly
Gains: ◦ Queries don’t require many joins ◦ Performance gains, especially when processing queries that would require many joins in a normalised database ◦ Faster and easier aggregation of data
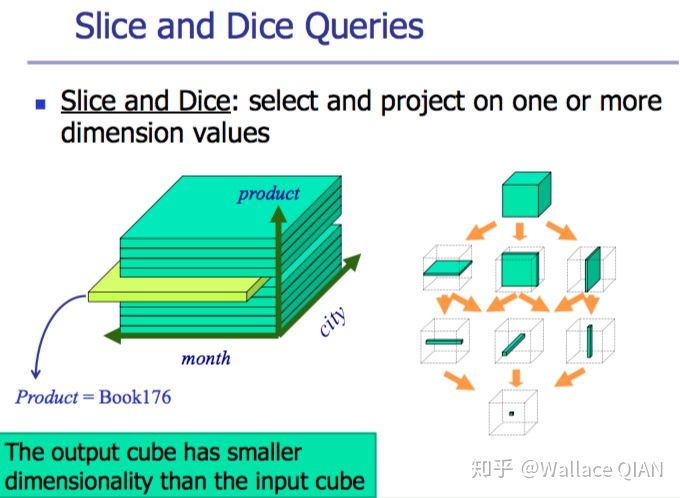
Data-Mining
基于OLAP。不仅仅是单纯的query,而是找到数据之间的关系。

Types of Discovered Knowledge 挖掘出的东西:
Association rules 相互关联的规则
Classification hierarchies 分类分层
Sequential patterns 序列模式(因果关系)
Clustering 聚类
market-basket model 购物篮模型
Data that can be described by: ◦ A set of items I ◦ A set of baskets B: each basket b ∈ B is a subset of I
\(I =\{o_1,o_2,o_3,\cdots\}\) , \(b_i⊆I\) , \(B=\{b_1,b_2,b_3,\cdots\,b_n\}\)
Support of an Itemset
考虑一个Itemset \(J\), \(J⊆I\) ,则:
Support of \(J\) = \(\sum\{b|b\cap J=J\}/n\)
更复杂的购物篮:
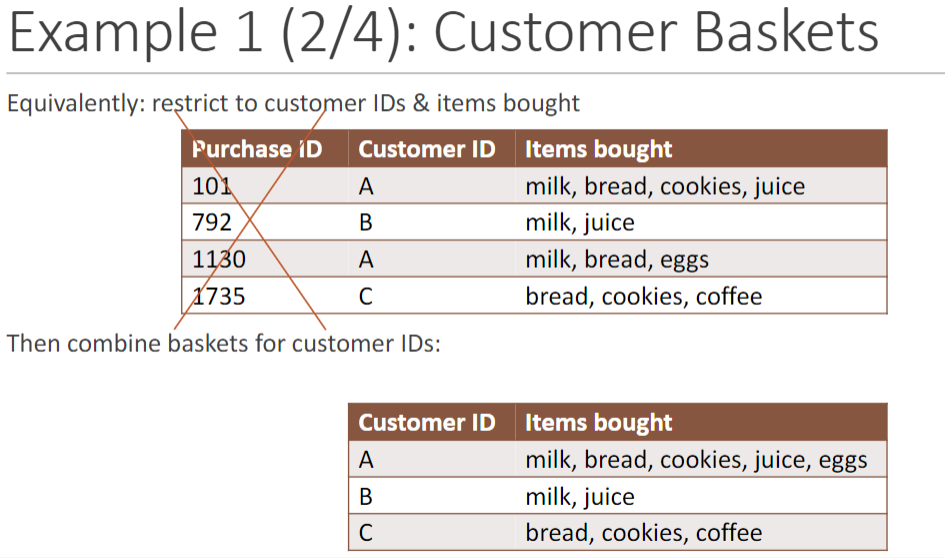
Support of {milk, bread}: ◦ With respect to the purchases = 2/4 = 0.5 ◦ With respect to the customers = 1/3 ≈0.33
With support threshold s = 0.5 ◦ {milk, bread} is frequent with respect to the purchases ◦ {milk, bread} is not frequent with respect to the customers
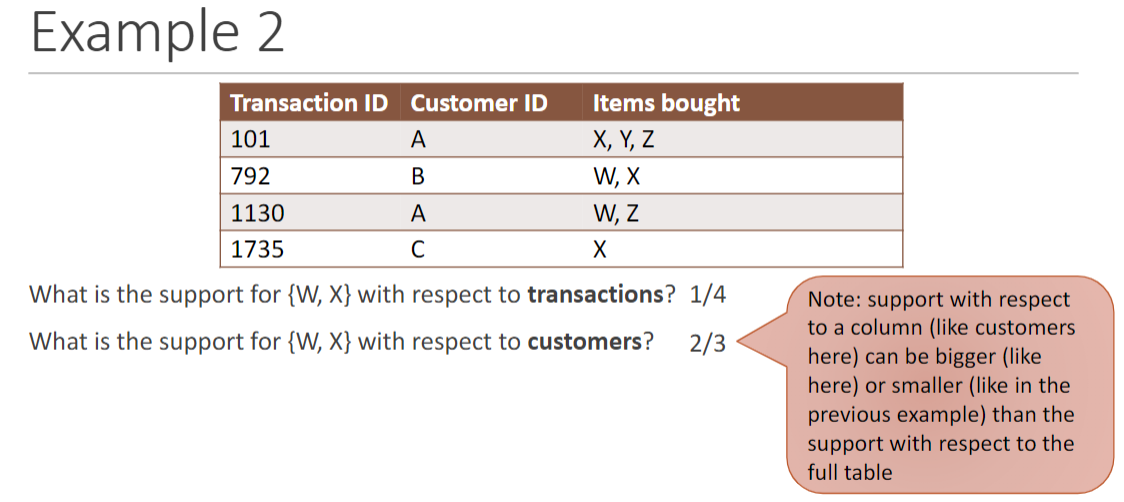
Association Rules 挖掘
Confidence: percentage of baskets for \(J_1\) containing \(J_2\)
General form: \(J_1 ⇒J_2\) , 有: \[ J_1 ⇒J_2 = \frac{Support\ of\ (J_1 \cup J_2)}{Support\ of\ J_1} \] 我们会认为设定一个 threshold 阈值 s
若\(J_1 ⇒J_2 ≥ s\) 则称其是 high enough
A-Priori Algorithm 先验算法
If \(J\) has support ≥ s, then all subsets of \(J\) have support ≥ s.